对数据集进行预处理时,首先根据数据类型将特征分为连续特征和分类特征。其中,针对连续特征最关键的预处理即为归一化(regularity),而针对分类特征最关键的预处理为编码(encoding)处理。
Continuous Feature: Scaler
- 为什么需要进行归一化?
- 一些分类器需要计算样本之间的 距离 (如欧氏距离),例如KNN。如果一个特征值域范围非常大,那么距离计算就主要 取决于这个特征 ,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)
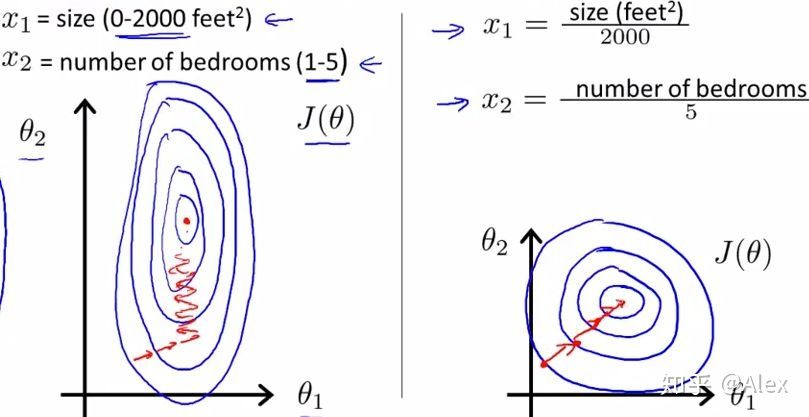
- 一些分类器需要计算样本之间的 距离 (如欧氏距离),例如KNN。如果一个特征值域范围非常大,那么距离计算就主要 取决于这个特征 ,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)
蓝色代表特征的等高线。在未归一化的情况下左图的两特征等高线相差较大,在进行度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛; 而右图对两个原始特征进行了归一化,其对应的等高线显得很圆,在梯度下降进行求解时能较快的收敛。因此如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。
-
归一化的类型
- Standard scaler:转化函数为, 经过处理的数据符合标准正态分布,即均值为0,标准差为1.
- Min-max scaler: 转化函数为,适用在数值比较集中的情况。该方法的缺陷在于如果max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。实际使用中可以用经验常量值来替代max和min
- Max-absolute scaler: 转化函数为.将值缩放到[-1,1]区间内, 不会破坏矩阵的稀疏性,因此比较适合稀疏矩阵和均值在0附近的值
- Non-linear scaler: 经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。该方法包括 log、指数,正切等
-
归一化使用注意事项:在实际预处理中,为了防止数据泄露,应使用训练集数据构建Scaler,在验证集/测试集上进行归一化。
-
面试相关问题:
-
Q: 哪些机器学习算法不需要做归一化处理?
A: 树模型不需要归一化。更广义地说,概率模型不需要归一化。因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率。而像svm、KNN、KMeans之类的最优化问题就需要归一化。树模型不需要归一化的原因是数值缩放不影响分裂点位置。因为当树的一个节点分裂时,都是按照特征的值进行排序的。如果排序的顺序不变,那么分裂点就不会有不同。但是对于线性模型,比如说LR,有两个特征,一个是(0,1)的,一个是(0,10000)的,这样运用梯度下降时候,损失等高线是一个椭圆的形状,这样想迭代到最优点,就需要很多次迭代,但是如果进行了归一化,那么等高线就是圆形的,那么SGD就会往原点迭代,需要的迭代次数较少。 另外,注意树模型是不能进行梯度下降的,因为树模型是阶跃的,阶跃点是不可导的,并且求导没意义,所以树模型(回归树)寻找最优点是通过寻找最优分裂点完成的。
-
Q: SVM和LR需要不需要归一化?
A: 有些模型在各维度进行了不均匀的伸缩后,最优解与原来不等价(如SVM)需要归一化。有些模型伸缩有与原来等价,比如LR。但是实际中往往通过迭代求解模型参数,如果目标函数太扁(想象一下很扁的高斯模型)迭代算法会发生不收敛的情况,所以最好进行数据归一化。 补充:其实本质是由于loss函数不同造成的,SVM用了欧拉距离,如果一个特征很大就会把其他的维度dominated。而LR可以通过权重调整使得损失函数不变。
-
Categorial Feature: encoding
常用的encoding方式有以下三种:
- Ordinal Encoding(序数编码): 即将分类编码为数值,适用于二元的变量或分类本身有定性排序的情况。
- One-hot Encoding(独热编码): One-Hot 编码会创建新列,指示原始数据中每个可能值的存在(或不存在)。与序数编码相比,one-hot 编码不假设类别的排序。
OHE的缺陷也很明显,编码后会使得空间维度大大增加,尤其是在类别很多的时候,这大大地扩展特征空间,使得训练难以进行。- 对数值大小不敏感的模型(如树模型)不建议使用。一般这类模型为树模型。如果分类类别特别多,那么
OHE会分裂出很多特征变量。这时候,如果我们限制了树模型的深度而不能向下分裂的话,一些特征变量可能就因为模型无法继续分裂而被舍弃损失掉了。 OHE在对n个分类进行n维稀疏的同时会导致多重共线性的出现,实际只需要n-1个编码即可表示。因此也会在实际操作中先删去一维变量再进行编码
- Target Encoding(目标编码):当定性特征的维度(Cardinality)很大时,上述两种方法都不能实现很好的编码效果。此时需要通过Target encoding进行编码。以二分类数据集为例,target encoding对于某一特征取值的编码是在该取值的全部观测值中标签1出现的占比。对回归数据来说,encoding可以是在该分类取值下的目标均值。
- 当极端情况出现时,该编码方法可能会导致数据泄露。如各个分类取值的比例和目标标签的相关性为1时可能会过拟合训练集输出的情况。