试图通过整理解决目前遇到过的HashMap全部问题。
底层数据结构
HashMap是由数组+链表+JDK1.8中增加的红黑树(当链表长度大于8时转换为红黑树)实现的。
在Java中,数据结构的物理存储只有数组好链表两种方式且各有优势,其中数组存储区域连续,因此查找快,由于增删要改动整个数组,因此增删慢;而链表反之。将数组和链表结合在一起,构成既满足查找快也满足增删块的基本数据结构,就构成了HashMap.
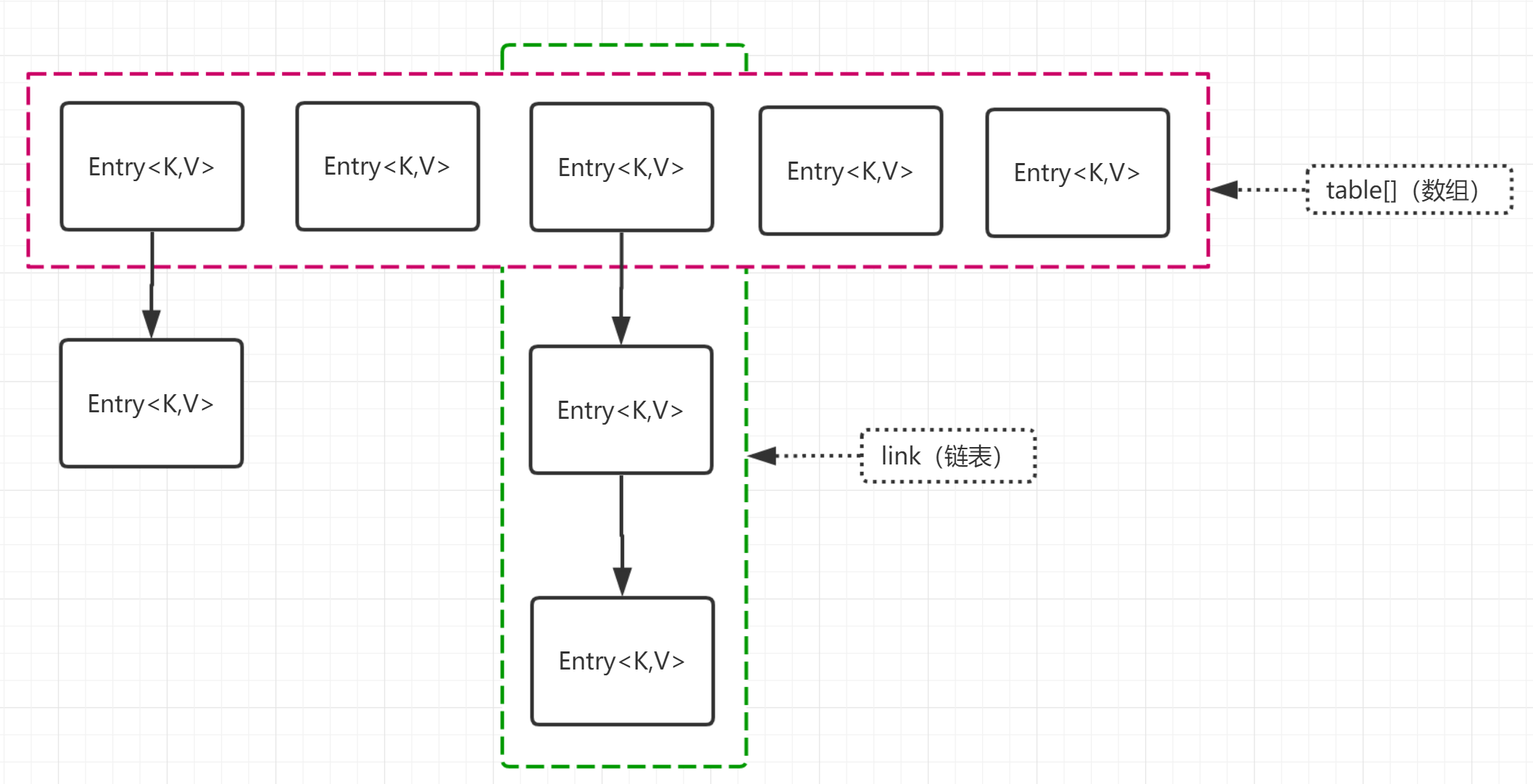
- HashMap中最基本的单元是Entry。
- 数组中Entry的“寻位”使用的是HashCode,通过对Key值进行Hash得到数据在数组中存放的下标获得位置。
1 | static class Node<K,V> implements Map.Entry<K,V> { |
- Node[] table,在逻辑结构中表现为用于存放Node的数组。Node为实现Map中Entry接口的键值对。
在HashMap中还定义了几个比较重要的字段(分别对应相关的属性),具体源码如下:
1 | public class HashMap<K,V> extends AbstractMap<K,V> |
- 其中,初始容量和负载因子可以通过设置initialCapacity和loadFactor的值进行修改。例如在内存空间较多,时间效率要求较高的特殊情况下,可以降低负载因子的值;反之可增加负载因子的值。
解决冲突
HashMap通过Hash算法来解决冲突。Java的HashMap采用了链地址法,即上图中链表和数组的结合。
当有新的键值对需要被放入HashMap时,采用Hash算法对Key进行运算后可以得到数组下标,之后将键值对放在对应下标元素的链表上即完成HashMap的存储功能。
- 当两个Key的Hash值相同时,在table数组中会定位到相同的位置,此时即发生了Hash碰撞。解决碰撞的方法除链地址法以外,还可以通过开放地址法实现(即当某个槽位已满时,通过其他放大继续查找下一个可以使用的槽位。e.g.线性探测法,二次散列探测法)
- Java在HashMap中形成但链表的核心设计在于,总是将新添加的Entry对象放入table数组的索引处。具体添加方式要依次进行以下判断:
- table是否为空
- 该位置是否已经存在Key
- 对应的Key是否为treenode(已经变为红黑树的存储结构)
- 链表长度是否大于8(是否需要变为红黑树的存储结构)
- 在没有出现Hash冲突时,HashMap查找元素很快;但出现单链表之后,需要在同一个bucket中对Entry链进行遍历才能找到需要的元素(最坏情况是该Entry是最早放入bucket中的元素)。